Uczenie maszynowe to jedna z najszybciej rozwijających się dziedzin sztucznej inteligencji. Coraz więcej firm i organizacji dostrzega ogromny potencjał, jaki dają algorytmy uczenia maszynowego w optymalizacji procesów i podejmowaniu trafnych decyzji. W niniejszym artykule przybliżymy kluczowe zagadnienia związane z tym fascynującym obszarem wiedzy. Omówimy podstawowe pojęcia, etapy budowy modeli predykcyjnych, popularne algorytmy, a także praktyczne przykłady zastosowań uczenia maszynowego.
Podstawowe koncepcje uczenia maszynowego
Aby móc swobodnie poruszać się po świecie uczenia maszynowego, musimy najpierw poznać kluczowe pojęcia i zależności. Przede wszystkim warto zrozumieć, czym uczenie maszynowe różni się od programowania. W przypadku programowania instruujemy komputer jak ma działać krok po kroku. Natomiast w uczeniu maszynowym budujemy model, który samodzielnie wyciąga wnioski i uczy się na podstawie przykładów.
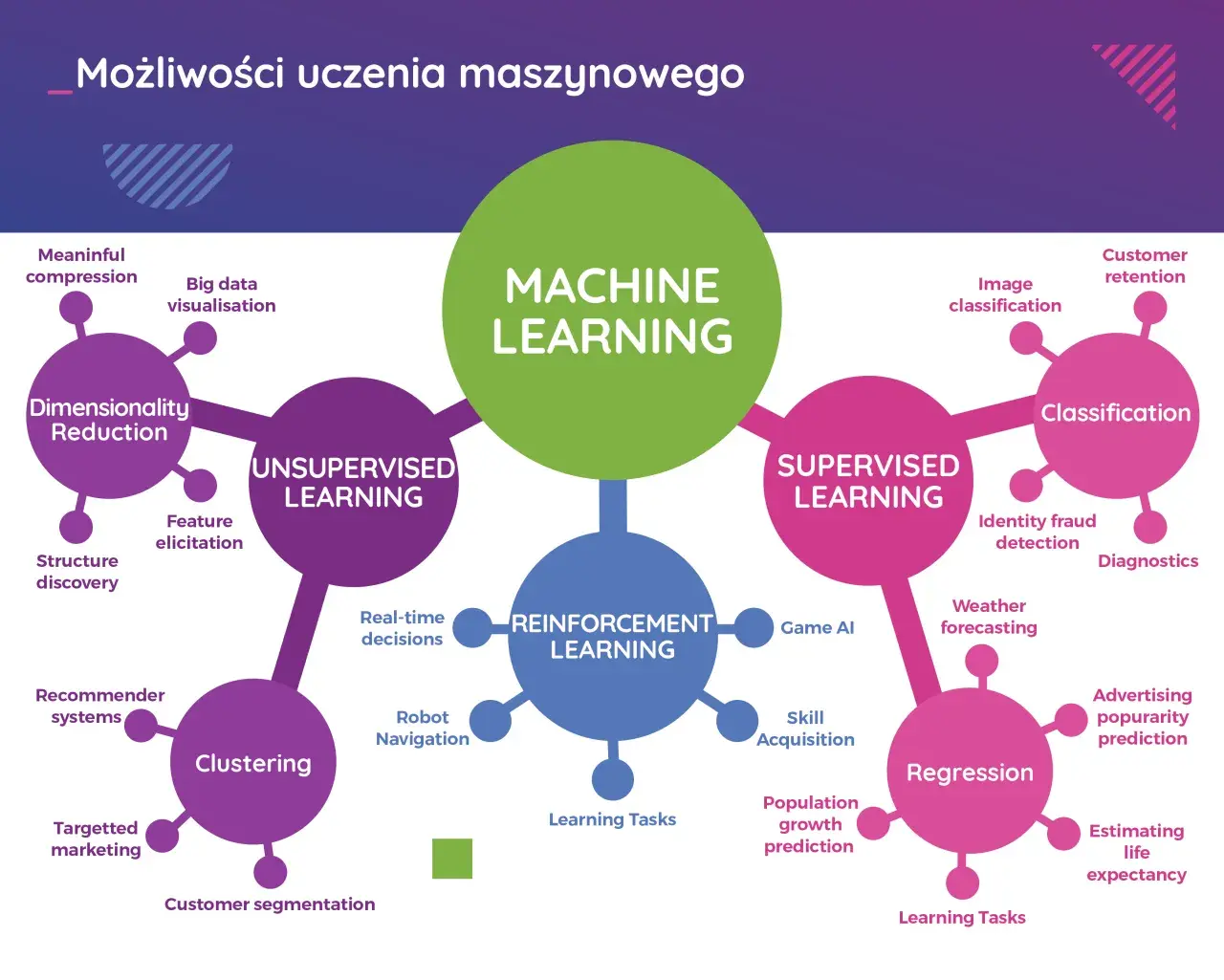
Kolejny ważny podział to uczenie nadzorowane i nienadzorowane. W uczeniu nadzorowanym model trenujemy na oznaczonych danych, podając mu poprawne odpowiedzi. Natomiast w nienadzorowanym, model sam organizuje dane bez podpowiedzi z zewnątrz. Jeszcze inną kategorią jest uczenie wzmacniane, gdzie model poprzez interakcję ze środowiskiem uczy się optymalnych działań.
Typy problemów uczenia maszynowego
W zależności od typu problemu, stosujemy odpowiednie modele i algorytmy uczenia maszynowego. Do najpopularniejszych typów zadań należą: klasyfikacja, regresja, klastering oraz redukcja wymiarowości.
Testy walidacyjne
Aby ocenić jakość modelu, stosujemy podział danych na zbiór uczący, walidacyjny i testowy. Pozwala to uniknąć problemu przeuczenia i zbyt optymistycznej oceny modelu. Testy walidacyjne są kluczowe w budowaniu użytecznych systemów uczenia maszynowego.
Naduczenie i niedouczenie
Dostrajanie modelu do danych uczących, przy jednoczesnej utracie zdolności generalizacji to naduczenie. Z kolei zbyt prosty model, niewykorzystujący całego potencjału danych to niedouczenie. Trzeba znaleźć złoty środek, aby model dobrze radził sobie zarówno na danych uczących, jak i nowych.
Przygotowanie danych do uczenia maszynowego
Przygotowanie danych jest kluczowym etapem każdego projektu z zakresu uczenia maszynowego. Im lepsza jakość danych, tym lepsze rezultaty można uzyskać. Proces ten składa się z kilku kroków.
Zbieranie danych
Najpierw musimy pozyskać odpowiednią ilość rzetelnych danych. Możemy skorzystać z gotowych zbiorów, lub zgromadzić dane samodzielnie np. za pomocą ankiet, czujników czy eksperymentów.
Czyszczenie danych
Kolejny krok to usunięcie zbędnych, niepoprawnych lub niepełnych obserwacji. Chodzi o wyeliminowanie szumów, które mogą negatywnie wpłynąć na model.
Normalizacja danych
Często konieczne jest przeskalowanie danych, aby wszystkie cechy miały podobny zakres wartości. Ułatwia to modelowanie zależności. Popularne metody normalizacji to standaryzacja i skalowanie min-max.
Czytaj więcej: Budowanie i trening modeli Machine Learning - poradnik dla początkujących
Modele uczenia maszynowego
Istnieje wiele modeli uczenia maszynowego. Różnią się złożonością, sposobem działania i typami problemów, do których są przystosowane. Omówmy trzy główne kategorie.
Uczenie nadzorowane
W uczeniu nadzorowanym mamy oznaczone dane treningowe, na podstawie których model uczy się przewidywać wartość docelową. Przykłady to regresja logistyczna, drzewa decyzyjne, czy sieci neuronowe.
Uczenie nienadzorowane
W tym przypadku, model sam organizuje dane bez z góry określonych poprawnych odpowiedzi. Przykłady zastosowań to wykrywanie anomalii, czy grupowanie klientów.
Uczenie wzmacniane
Model poprzez interakcję ze środowiskiem uczy się optymalnych działań, które maksymalizują zdefiniowaną nagrodę. Zastosowanie w robotyce, grach i systemach rekomendacyjnych.
Algorytmy uczenia maszynowego
Istnieje szeroka gama algorytmów uczenia maszynowego. Każdy charakteryzuje się innymi właściwościami i ograniczeniami. Omówmy popularne przykłady.
Regresja liniowa
Prosty, ale skuteczny model do prognozowania zmiennych ciągłych. Szacuje zależność liniową pomiędzy cechami objaśniającymi a zmienną docelową.
Drzewa decyzyjne
Drzewa decyzyjne modelują złożone zależności poprzez hierarchiczną segmentację przestrzeni cech. Ich zaletą jest prosta interpretacja działania.
Sieci neuronowe
Inspirowane biologią modele, które poprzez warstwy połączonych ze sobą neuronów uczą się złożonych zależności. Osiągają bardzo dobre wyniki w wielu zadaniach.
Wdrażanie i ewaluacja modeli
Po wytrenowaniu modelu, musimy go odpowiednio wdrożyć i monitorować jego skuteczność. Obejmuje to między innymi:
Podział danych
Rozdzielenie zbioru danych na uczący, walidacyjny i testowy w celu rzetelnej oceny modelu.
Metryki ewaluacji
Dobór odpowiednich miar jakości modelu, takich jak accuracy, precyzja, recall w zależności od typu problemu.
Optymalizacja hiperparametrów
Dostrojenie hiperparametrów modelu (np. liczby warstw sieci neuronowej), aby zmaksymalizować jego skuteczność.

Zastosowania uczenia maszynowego
Zastosowania praktyczne uczenia maszynowego są niezwykle szerokie. Obejmują m.in.:
Rekomendacje
Systemy rekomendujące filmy, produkty, czy artykuły dopasowane do konkretnego użytkownika.
Przetwarzanie języka naturalnego
Rozpoznawanie i synteza mowy, tłumaczenia automatyczne, czy analiza sentymentu.
Systemy autonomiczne
Samochody autonomiczne, robotyka, czy inteligentne systemy wsparcia decyzyjnego.
Podsumowując, uczenie maszynowe to ekscytująca i szybko rozwijająca się dziedzina, która znacząco wpływa na wiele sfer naszego życia. Mamy nadzieję, że niniejszy artykuł pozwolił przybliżyć Państwu tę tematykę i zachęcił do pogłębienia wiedzy w tym fascynującym obszarze.
Podsumowanie
Uczenie maszynowe to niezwykle szeroka i dynamicznie rozwijająca się dziedzina sztucznej inteligencji. Choć wymaga solidnej wiedzy matematycznej i programistycznej, opłaca się zainwestować w jej zgłębianie. Model predykcyjny dobrze wdrożony może optymalizować procesy, generować oszczędności i stanowić przewagę konkurencyjną. Mamy nadzieję, że artykuł pozwolił przybliżyć najważniejsze zagadnienia związane z uczeniem maszynowym i zachęcił do praktycznego zastosowania tych fascynujących technik.